
Introduction
Small Language Models (SLMs) are revolutionizing AI by offering efficient, cost- effective alternatives to resource-heavy large language models (LLMs). With faster inference, lower latency, and easier deployment, SLMs are ideal for edge computing, domain-specific tasks, and scalable AI solutions. AEWIN provides various kinds of Edge Computing Server to enable AI workloads required for SLM innovations.
What are Small Language Models (SLMs)?
Small Language Models (SLMs) are compact versions of large language models, designed to deliver competitive performance with significantly fewer parameters. Unlike LLMs, which often require massive computational resources and datasets, SLMs are lightweight, energy-efficient, and easier to fine-tune for specific tasks.
– Prominent SLMs
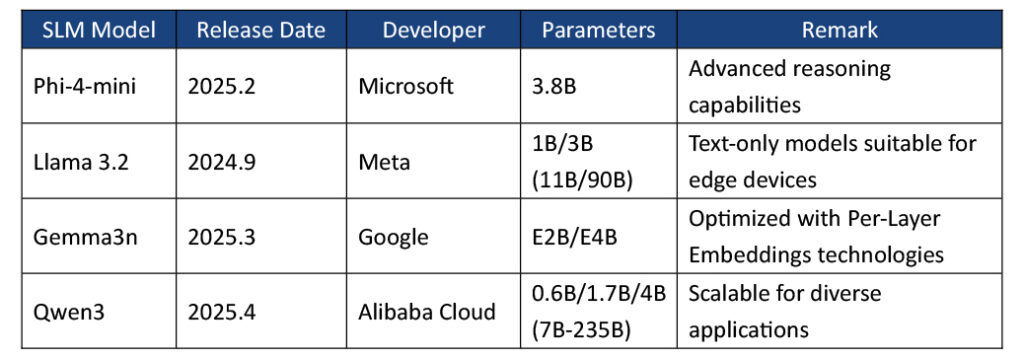
– Phi-4-mini: Phi-4-mini-instruct is a lightweight open model in the Phi-4 family. Enhanced through supervised fine-tuning and direct preference optimization, it features strong reasoning performance especially as math and logic for general-purpose AI applications.
– Llama 3.2: Developed by Meta, Llama 3.2 includes 1B and 3B parameter text-only models optimized for edge devices, and 11B and 90B parameter vision models for advanced visual understanding tasks while Llama 4 is focusing on LLM with up to 17B active parameters and 400B total parameters.
– Gemma 3n: The public release includes E2B and E4B variants (5B and 8B nominal parameters) that operate on a smaller effective scale. Leveraging innovative Per-Layer Embeddings (PLE) technique, Gemma 3n features reduced memory usage and improved compute efficiency to allow developers to deploy generative AI on edge devices.
– Qwen3: Developed by Alibaba Cloud, Qwen3 is a versatile AI model starting with only 0.6B parameters which is the smallest one among the most common SLM listed in the table above while it still can support 119 languages for NLP. The family scales to larger variants for flexible uses across diverse AI applications.
Why SLMs Matter in the AI Landscape
SLMs address several challenges associated with LLMs, including:
- Fast, Low-Latency Inference: With far fewer parameters to process, SLMs require significantly reduced processing power and can run smoothly and efficiently at edge. Rapid inference with real-time interactions is achievable at where the data is generated which brings innovative applications such as conversational AI, anomaly detection, industrial control, cybersecurity threat response reality.
- Easier Deployment: SLMs are lightweight enough to run across a wide spectrum of hardware platforms, from Edge AI servers to CPU-only servers and edge devices. Their smaller memory footprint and reduced system requirements make deployment in diverse edge without massive infrastructure upgrades.
- Cost Efficiency: With affordable hardware solutions and less consuming power required, SLMs drastically lower both capital and operational expenses. Organizations can scale AI capabilities while keeping costs of compute and cooling under control. It may broaden the adoption of related Edge AI applications across industries.
AEWIN Edge AI Servers Empower SLMs
AEWIN’s edge AI servers are designed to accommodate a wide range of GPU cards in a compact and short-depth 2U chassis that allow customers to choose the hardware solution best fits their requirements, whether it’s CUDA-optimized NVIDIA GPUs or open-source ecosystems like ROCm for AMD GPUs. AEWIN servers provide the computational power needed to train and fine-tune SLMs efficiently.
AMD has conducted a demonstration tech blog showing the works of running Phi-2 on MI210 accelerator. The results show that there is excellent performance in generating code, summarizing papers, and generating text in a specific style. AEWIN SCB-1946C has been verified with dual MI210 for optimized performance to accelerate SLM workloads in on-premises networking, storage, and edge computing applications.
As AI continues to evolve, the demand for efficient and scalable solutions will continue to grow. SLMs reflect a shift toward more accessible AI, and AEWIN’s Edge AI servers are ready to support this transition. By combining the efficiency of SLMs with AEWIN’s reliable and high-performance platforms, organizations can build AI infrastructures that are ready to scale, while maintaining cost efficiency.
Summary
Small Language Models are redefining how AI is deployed by delivering sufficient performance with significantly lower compute and energy requirements. To fully realize their potential across edge environments, SLMs require hardware platforms that balance compute density, scalability, and deployment flexibility. AEWIN’s reliable and flexible edge servers provide a practical foundation for cost-effective and scalable AI deployments.